Finally successful in installing Informatica on my PC. :)
OS - Windows 7
Informatica version 8.6.1
Installation of Informatica Server:
Below is the list of issues faced during installation and their remedies:
1. During Server Installation - Click the option "Windows SP3" to make it compatible to OS.
2. During Server Installation: Informatica Services not starting
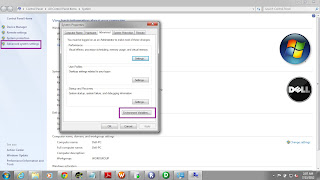
Set the Variables
JAVA_HOME = C:\Program Files\<Java.exe path>
JRE_HOME=C:\Program Files\Java\<JRE>
PATH=C:\Informatica\PowerCenter8.6.0\server\bin;

Once the following prerequisites are completed, start the Server installation.
TIP: Browse to the install.exe file and "Run as administrator"
From the drop-down list, select OS as "Windows Service Pack 3"
Once, the Server setup is completed, go to Services.msc and check the Informatica Services.
If the status is Started, your installation was successful.
Else, close windows firewall and then restart the service.

We will configure and start Repository Services in the next Blog !!
We will also create ODBC connection between Teradata and Informatica.
Please let me know your doubts/comments .
OS - Windows 7
Informatica version 8.6.1
Installation of Informatica Server:
Below is the list of issues faced during installation and their remedies:
1. During Server Installation - Click the option "Windows SP3" to make it compatible to OS.
2. During Server Installation: Informatica Services not starting
- Install Java, JRE and Apache Tomcat in your PC.
- Go to My Computer -> Properties -> Advanced system Settings

Set the Variables
JAVA_HOME = C:\Program Files\<Java.exe path>
JRE_HOME=C:\Program Files\Java\<JRE>
PATH=C:\Informatica\PowerCenter8.6.0\server\bin;

Once the following prerequisites are completed, start the Server installation.
TIP: Browse to the install.exe file and "Run as administrator"
From the drop-down list, select OS as "Windows Service Pack 3"
Once, the Server setup is completed, go to Services.msc and check the Informatica Services.
If the status is Started, your installation was successful.
Else, close windows firewall and then restart the service.

We will configure and start Repository Services in the next Blog !!
We will also create ODBC connection between Teradata and Informatica.
Please let me know your doubts/comments .

